How To Save Data From Help Scout’s API to CSV in Python
There are many times when you need to download data from an API and store it into a CSV. Perhaps, you want to analyze some data. Or, you want to combine the data with other data sets.
In this article, we are going to explore how to do this while using Help Scout's API. Help Scout is a help desk solution that teams use when communicating with their customers.
We will retrieve the "conversations" from one of our Help Scout mailboxes and store that data into a CSV. These conversations will include who sent the email, the subject, dates, which of our team members were assigned the conversation, and when it was closed.
Getting Your App ID and Secret
Before we can begin getting data from the Help Scout API, we need to generate an app ID and secret. First, log into HelpScout and go to "Your Profile."
Click the "My Apps" in the left menu.
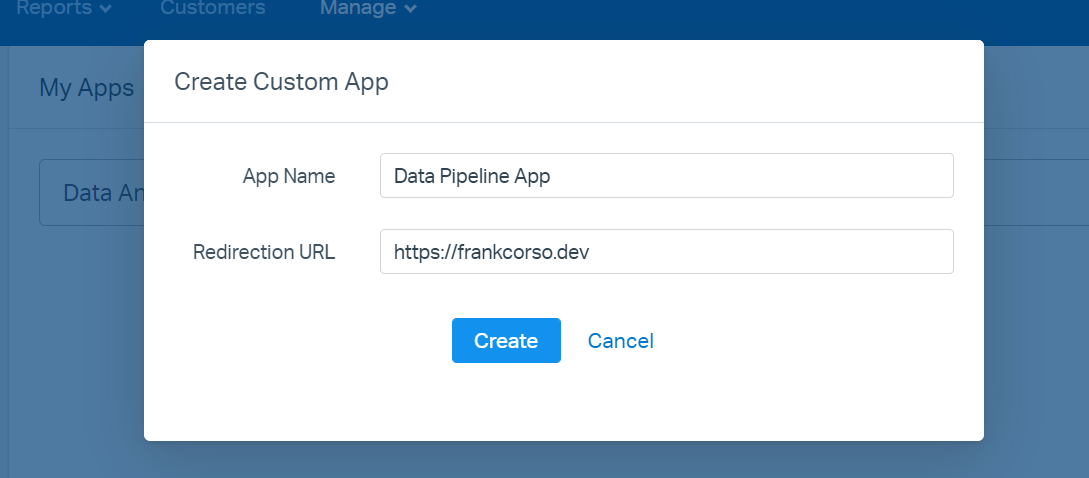
Click the "Create My App" button and fill in a name. Since we won't have users authenticating with this app, you can enter any URL for the redirect. I usually just put the URL for the company's site.
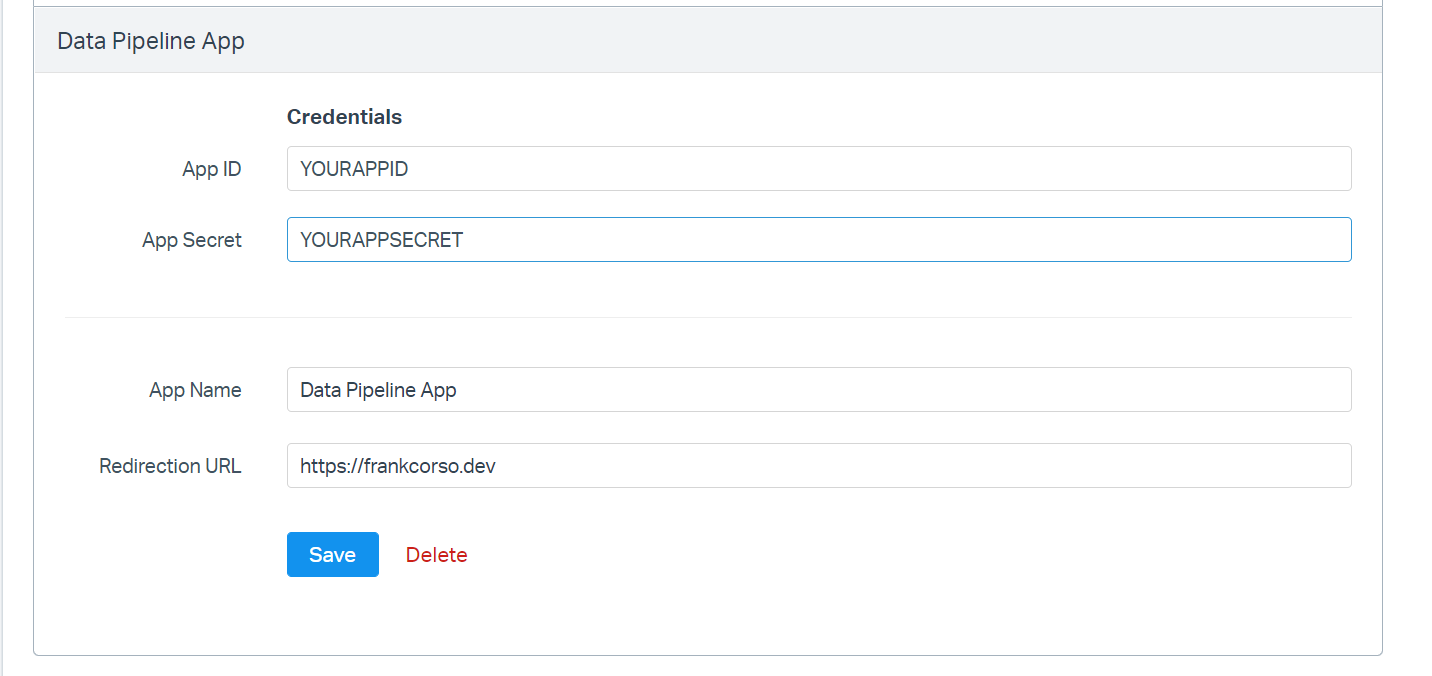
Click the "Create" button. Once created, you will see your app's ID and Secret.
While in Help Scout, open the mailbox you want to retrieve the conversation for. In the URL, you will find the mailbox's ID, which we will need later:
Getting Your Access Token
Since we won't be authenticating users, we will use Help Scout's client credentials flow for authentication. To do so, we first need to get an access token.
First, we need to import any packages we need. I almost always use the "requests" package when working with APIs. Additionally, since we have the created time and closed time, I like to go ahead and calculate resolution time here. To do so, I will use Python's "datetime" library.
import csv
import datetime
import requests
Next, we need to send our app's ID and secret to their token endpoint. We can do this by making a request and getting the access_token key from the JSON they return.
# The token endpoint.
auth_endpoint = 'https://api.helpscout.net/v2/oauth2/token'
# Preparing our POST data.
post_data = ({
'grant_type': 'client_credentials',
'client_id': YOUR_HELPSCOUT_APP_ID,
'client_secret': YOUR_HELPSCOUT_APP_SECRET
})
# Send the data.
r = requests.post(auth_endpoint, data=post_data)
# Save our token.
token = r.json()['access_token']
We need way to keep going through our loop until we have downloaded all the conversations. The Help Scout api contains a totalPages key that we can check against.
There are a few different ways we could handle this but I like to just set a self-explanatory flag to false.
all_conversations = False
page = 1
Then, we need to prepare our authorization headers.
# Prepare our headers for all endpoints using token.
endpoint_headers = {
'Authorization': 'Bearer {}'.format(token)
}
Preparing the CSV File
Now that we have our token, we can set up our CSV file. If you haven't worked with CSV's in Python before, check out my "Reading From and Writing to CSV Files in Python" article.
First, open our CSV file and write the header:
# Creates our file or rewrites it if one is present.
with open('conversations.csv', mode="w", newline='', encoding='utf-8') as fh:
# Define our columns.
columns = ['ID', 'Customer Name', 'Customer email addresses', 'Assignee', 'Status', 'Subject', 'Created At',
'Closed At', 'Closed By', 'Resolution Time (seconds)']
csv_writer = csv.DictWriter(fh, fieldnames=columns) # Create our writer object.
csv_writer.writeheader() # Write our header row.
Downloading Our Conversations and Putting Them Into the CSV
Now that we have our access token and our CSV opened, it's time to retrieve the conversations. Help Scout's Mailbox API has a "List Conversations" endpoint that sends over the conversations in a paginated format. You can view all of the available parameters for the endpoint in their endpoint developer documentation.
Remember to keep all of this indented inside the with open() statement so we can write to our CSV.
Inside a while loop, we will get our first page of conversations:
while not all_conversations:
# Prepare conversations endpoint with the status of conversations we want and the mailbox.
conversations_endpoint = 'https://api.helpscout.net/v2/conversations?status=all&mailbox=YOUR_MAILBOX_ID&page={}'.format(
page
)
r = requests.get(conversations_endpoint, headers=endpoint_headers)
conversations = r.json()
Next, we will cycle over each of the conversations within this page to save them to the CSV. Since there are many keys in the JSON that might be missing depending on the conversation, we need to clean and process the data just enough to save it.
# Cycle over conversations in response.
for conversation in conversations['_embedded']['conversations']:
# If the email is missing, we won't keep this conversation.
# Depending on what you will be using this data for,
# You might omit this.
if 'email' not in conversation['primaryCustomer']:
print('Missing email for {}'.format(customer_name))
continue
# Prepare customer name.
customer_name = '{} {}'.format(
conversation['primaryCustomer']['first'],
conversation['primaryCustomer']['last']
)
# Prepare assignee, subject, and closed date if they exist.
assignee = '{} {}'.format(conversation['assignee']['first'], conversation['assignee']['last']) \
if 'assignee' in conversation else ''
subject = conversation['subject'] if 'subject' in conversation else 'No subject'
closed_at = conversation['closedAt'] if 'closedAt' in conversation else ''
# If the conversation has been closed, let's get the resolution time and who closed it.
closed_by = ''
resolution_time = 0
if 'closedByUser' in conversation and conversation['closedByUser']['id'] != 0:
closed_by = '{} {}'.format(
conversation['closedByUser']['first'], conversation['closedByUser']['last']
)
createdDateTime = datetime.datetime.strptime(conversation['createdAt'], "%Y-%m-%dT%H:%M:%S%z")
closedDateTime = datetime.datetime.strptime(conversation['closedAt'], "%Y-%m-%dT%H:%M:%S%z")
resolution_time = (closedDateTime - createdDateTime).total_seconds()
Then, write our results to the CSV:
# Write row to CSV
csv_writer.writerow({
'ID': conversation['id'],
'Customer Name': customer_name,
'Customer email addresses': conversation['primaryCustomer']['email'],
'Assignee': assignee,
'Status': conversation['status'],
'Subject': subject,
'Created At': conversation['createdAt'],
'Closed At': closed_at,
'Closed By': closed_by,
'Resolution Time (seconds)': resolution_time
})
Lastly, check their 'totalPages' key against the page we are on to see if we have retrieved all the conversations. If not, increment the current page and then we'll start the process over again.
if page == conversations['page']['totalPages']:
all_conversations = True
continue
else:
page += 1
Great! We now have our script ready to run. You can see all this code together in my GitHub gist here.
Next Steps
Go ahead and run your script to retrieve all the conversations from your Help Scout mailbox.
If you were looking to just get a backup, then you are good to go. If you wanted the data to perform data analysis, you can now open the file in Excel or use pandas with it. Or, if this was the first step of your data pipeline, you could now start working on the next step in the pipeline.
Similar Articles
How To Create an Endpoint for an AWS Lambda Function Using API Gateway
Need to send and retrieve data from your AWS Lambda function via HTTP request? Learn how to create an endpoint that connects to it using AWS API Gateway.
Using AWS Glue to Convert CSV Files to Parquet
Learn how to harness the power of AWS Glue's fully managed ETL service to effortlessly convert CSV files to Parquet format while performing data transformations.